本記事の注意
- 僕はまだ論文の中身までは目を通してません。
- 説明は適当です。
- 記号の意味
- 「」: 僕の発言
- 🔴: 主観的興味
- 🔵: 客観的興味
- 🟡: 将来、好きになりそう
- 🟣: 自分の取り組みに関連する
- ICLR 2024 の論文一覧には載ってないけどまだ採択が決まっていない論文があるっぽい?
アーキテクチャ系
全体的に
- Merge, Then Compress: Demystify Efficient SMoE with Hints from Its Routing Policy (spotlight) 🟡
- 複数の Expert を、知識豊富な少数の Expert に統合するには、どのような方法があるのだろうか?
- 従来の統合法は、有効でないため、新しいマージアルゴリズムを提案する。
- Expert のニューロンの順番を揃える
- 支配的な Expert とそのグループメンバーを形成する
- 各 Expert の活性化頻度を重みとしてグループメンバーをマージする
- Simplifying Transformer Blocks 🟣
- 「LayerNorm 要らないってまじか」
![]()
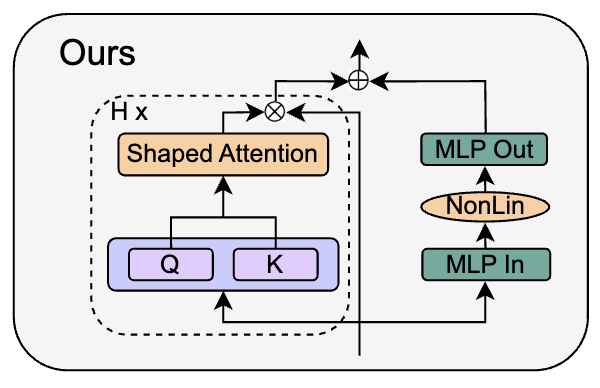
部分的に
- ReLU Strikes Back: Exploiting Activation Sparsity in Large Language Models (oral) 🔵
- 最近の傾向として、GELU や SiLU のような、計算量が増えることで知られる代替活性化関数が支持されているが、本研究では、LLM において ReLU 活性化を復活させることを強く提唱する。
- Think before you speak: Training Language Models With Pause Tokens 🔴
<pause-token>が出力されている間は、モデルの出力の抽出を遅らせることで、答えにコミットする前に追加の計算を処理することを可能にする。- 「モデルに考える時間をあげるイメージ?」「arxiv 見たことある。発想が好きだったやつ」
- Scaling Laws of RoPE-based Extrapolation 🟣
- RoPE に基づく LLM の事前学習において、文脈長を小さくするか大きくするかを微調整することで、外挿性能が大幅に向上することを確認した。
- 基数と外挿性能の関係や、RoPE に基づく外挿問題の起源を説明する。
- LLaMA2 7B と 13B において、わずか 16K の学習長で 100 万コンテキスト長までの外挿を達成した。
- Lightweight Language Model Calibration for Open-ended Question Answering with Varied Answer Lengths 🔵
- LLM のキャリブレーションは幻覚を検出・軽減し、より信頼できるモデルを構築する上で重要な役割を果たすため、極めて重要である。
- キャリブレーション: モデルの確率推定値を真の尤度と一致させること。
- 「言語処理学会でもバイアス項をいじると生成文の雰囲気が変わるという話があった。かなり重要なパーツっぽい」
- Transformer Language Models Handle Word Frequency in Prediction Head (Kobayashi et al., Findings 2023)
- LLM のキャリブレーションは幻覚を検出・軽減し、より信頼できるモデルを構築する上で重要な役割を果たすため、極めて重要である。
学習手法系
事前学習について
- Headless Language Models: Learning without Predicting with Contrastive Weight Tying 🔴
- token の確率予測の代わりに Constrastive Weight Tying による対照学習で入力埋め込みを再構築する。
- 訓練に必要な計算量を最大 20 倍削減しつつ、下流の性能とデータ効率を向上させる
- GLUE スコアは+1.6、LAMBADA は+2.7
- 「人間は話す時にいつも単語を選んでいるわけではないという違和感を解消してくれるような手法。」
- 「arxiv 見たことある。好きだったやつ。」
- EMO: EARTH MOVER DISTANCE OPTIMIZATION FOR AUTO-REGRESSIVE LANGUAGE MODELING 🔵
- forward cross-entropy は次の理由から人間とモデルの分布を align させる距離指標として最適ではないことを立証する: (1) recall-prioritization, (2) negative diversity ignorance, (3) train-test mismatch
- auto regressive 言語モデリングのための EMO(Earth Mover Distance Optimization)を提案する。
- EMO は MLE よりも一貫して優れた言語モデリング性能を示す。
- EMO は、わずか 25,000 文の最小限の fine-tuning でも、ダウンストリーム性能の顕著な向上を示す。
- Exploring the Promise and Limits of Real-Time Recurrent Learning 🟡
- RTRL は過去の勾配を保存する必要がなく、任意の長さのシーケンスに対して切り捨てのない勾配を計算できる。
- RTRL はオンライン学習アルゴリズムだから、新しい入力を消費した直後に重みを更新できる。
- ただし、現在は実用レベルではないらしい。
- 「Real-Time Recurrent Learning というワードが気になった。推論しながら学習できるってこと?」
fine tuning について
- Tuning LayerNorm in Attention: Towards Efficient Multi-Modal LLM Finetuning (spotlight) 🟣
- 興味深いことに、各注意ブロック内では、LayerNorm をチューニングするだけで十分な性能が得られる。
- full-parameters fine tuning や LoRA 等と比較した場合、効率に対する LayerNorm の利点は大きい。
- 「fine tuning は LayerNorm だけで良いっていう話前も見たな」
- An Empirical Study on the Transferability of Transformer Modules in Parameter-efficient Fine-tuning (AkbarTajari et al., EMNLP 2022)
- Dissecting learning and forgetting in language model finetuning 🔵
- fine tuning は言語モデルのトピックとスタイルの事前分布を大きく変化させるが、実際の知識学習は確率変化のごく一部にしか寄与しないことが明らかになった。
- この研究は、言語モデルにおける学習と忘却のより細かいダイナミクスに関する洞察と理解を提供し、言語モデルの継続的学習におけるドメイン適応の改善と忘却の課題への対処に関する今後の研究に役立つ可能性がある。
- 「下の論文と主張が一致」
- What happens when you fine-tuning your model? Mechanistic analysis of procedurally generated tasks 🔵
- 小さな学習率で fine-tuning するありふれたプロトコルは、基本的なモデルの能力をほとんど変えない。
- 多くの場合、基礎となるモデル能力の上にある最小限の変換が新しい能力を学習する。
- 学習前の能力が関連するタスクで fine-tuning すると、サンプル効率の良い能力の``復活’‘につながる
- 下流のタスクで fine-tuning を行うだけで、実践者が意図せずに安全なモデルを安全でなくしてしまう可能性がある
- TinyStories データセットで学習した言語モデルの分析も行い、現実的な設定で我々の主張を裏付ける。
- 「上の論文と主張が一致」
LLM 系?
使い方について
- Let Models Speak Ciphers: Multiagent Debate through Embeddings 🟡
- トークンサンプリングステップは、語彙全体にわたるモデルの信念を表現するために 1 つのトークンしか使用しないため、潜在的な情報損失のリスクをもたらす。
- 我々は LLM からトークンのサンプリングステップを取り除き、生の transformer 出力埋め込み値の期待値を通して、語彙全体にわたって彼らの信念を伝達させる。
- これは、LLM 間のコミュニケーションのための代替言語としての埋め込みの優位性と頑健性を示している。
- 「言語を経由せずにテレパシーしたいってこと?」
- Demystifying Embedding Spaces using Large Language Models 🔵
- 埋め込みを解釈しやすくし、広く有用にするため、埋め込みと直接対話する LLM を採用し、抽象的なベクトルを理解可能なナラティブに変換する。
- 「埋め込みと会話することは果たして解釈性向上と繋がっているのか?」
- Tell Your Model Where to Attend: Post-hoc Attention Steering for LLMs 🔵
- 人間は太字や斜体等を利用して読者を誘導する。LLM と対話する際にも、同様のニーズがある
- ユーザが指定した情報、例えば指示により注意を払うようにモデルを誘導したい。
- 人間は太字や斜体等を利用して読者を誘導する。LLM と対話する際にも、同様のニーズがある
- SetCSE: Set Operations using Contrastive Learning of Sentence Embeddings 🔵
- SetCSE は、複雑なセマンティクスを表現するために集合を採用し、提供されたコンテキスト内で構造化された情報検索を行うために、明確に定義された操作を組み込んでいる。
挙動について
- Proving Test Set Contamination for Black-Box Language Models (oral) 🔵
- 交換可能なベンチマークの順序は、すべて等しく可能性があるはずである。対照的に、言語モデルは例の順序を記憶する傾向があるため、汚染された言語モデルは特定の正準順序が他の順序よりもはるかに可能性が高いと判断する。
- 我々のテストは、正準順序のベンチマークデータセットの尤度が、例をシャッフルした後の尤度よりも有意に高い場合に、汚染の可能性を検出する。
- Beyond Memorization: Violating Privacy via Inference with Large Language Models (spotlight) 🔵
- 一般的なプライバシー防止策、すなわちテキストの匿名化やモデルのアライメントは、LLM 推論からユーザーのプライバシーを保護する上で、現在のところ効果がないことを示す。
- Evaluating the Zero-shot Robustness of Instruction-tuned Language Models (spotlight) 🔵
- 新規の(観測されていないが)適切な命令文の使用は、一貫してモデルの性能を低下させ、時には大幅に低下させることがわかった。
- i.e., 命令チューニングされたモデルは、命令の言い換えに対して特に頑健ではない。
- 意味的に等価な命令の表現間の類似性を最大化するように最適化することで、命令チューニングモデルの頑健性が一貫して向上することを示す。
- 新規の(観測されていないが)適切な命令文の使用は、一貫してモデルの性能を低下させ、時には大幅に低下させることがわかった。
- The Reversal Curse: LLMs trained on “A is B” fail to learn “B is A” 🔴
- あるモデルが「A は Bである」という形の文に対して学習された場合、自動的に逆方向の「B は Aである」に汎化されることはない。
- Attention Satisfies: A Constraint-Satisfaction Lens on Factual Errors of Language Models 🔴
- Transformer ベースの LLM が事実と異なるテキストを生成する際の内部動作を調査する。
- その結果、LLM が制約トークンに注意を払うことと、事実誤認のない生成との間に強い正の関係があることを発見した。
- 我々は、事実誤認ときめ細かな制約充足を予測し、早期のエラー識別を可能にする、注意パターンをプローブする方法である SAT プローブを提案する。
Transformer の分析
- Are Transformers with One Layer Self-Attention Using Low-Rank Weight Matrices Universal Approximators? 🟡
- 先行研究では、Transformer はデータ記憶をするために、一般的に使用されているモデル以上にレイヤーが必要だとされていた。
- これは、ソフトマックス関数をハードマックス関数の近似として解釈していることに起因する。
- ソフトマックス関数とボルツマン演算子との関連を明らかにすることで、低ランクの重み行列を持つ自己注意の単一層が、入力シーケンス全体の文脈を完全に捉える能力を持つことを証明する。
- 結果として、1 層と 1 ヘッドの Transformer は有限サンプルに対して記憶能力を持ち、1 層の自己注意層と 2 つのフィードフォワードニューラルネットワークからなる Transformer は、コンパクトな領域上の連続関数に対して普遍的な近似器であることを示す。
- Linearity of Relation Decoding in Transformer Language Models (spotlight) 🟣
- Transformer 言語モデルに符号化される知識の多くは、単語とその同義語、実体とその属性などの関係で表現される。我々は、一部の関係については、主語表現に対する単一の線形変換によって、その計算は十分に近似されることを示す。
- Analyzing Feed-Forward Blocks in Transformers through the Lens of Attention Map (spotlight) 🟣
- FF ブロックをアテンションマップに表示することで、FF ブロックの入力文脈の視覚化効果を分析する。
- FF ネットワークは特定のタイプの言語構文を強調するように入力文脈化を変更することが明らかになった。
- FF とその周辺の構成要素は互いの効果を打ち消し合う傾向がある。
- Sudden Drops in the Loss: Syntax Acquisition, Phase Transitions, and Simplicity Bias in MLMs (spotlight) 🟡
- 構文注目構造(Syntactic Attention Structure:SAS)を研究する。
- SAS: 特定の Transformers ヘッドが特定の構文関係に注目する傾向。
- モデルが突然 SAS を獲得し、損失が急激に減少する、事前学習中の短いウィンドウを特定する。このブレークスルーが、その後の言語能力の獲得を促進する。
- 訓練中に SAS を操作することで、SAS の因果的役割を調べ、SAS が文法能力の発達に必要であることを示す。
- SAS は訓練中に他の有益な特性と競合し、SAS を短期間抑制することでモデルの質が向上することを見出した。
- 「induction heads の話とかなり似ている?」
- 構文注目構造(Syntactic Attention Structure:SAS)を研究する。
状態空間モデル系
- Inverse Approximation Theory for Nonlinear Recurrent Neural Networks (spotlight) 🔴
- 線形 RNN における記憶の呪いが一般的な非線形設定に拡張され、長期記憶を持つ順序関係を学習するための RNN アーキテクチャの本質的な限界が定量化される。
- この限界を克服するための原理的な再パラメータ化手法を提案する。
- 「state space もこの再パラメータ化手法に当てはまるらしい」
- 「state space は線形 RNN なので気になる。レビューを受けて state-space に付いての記述・引用を追加した模様」
- Robustifying State-space Models for Long Sequences via Approximate Diagonalization (spotlight) 🟣
- S4-PTD と S5-PTD モデルを提案する。
- 異なる初期化スキームの伝達関数の理論的解析を通して、S4-PTD/S5-PTD 初期化が HiPPO フレームワークに強く収束するのに対し、S4D/S5 初期化は弱い収束しか達成しないことを示す。
- Exploring the Relationship Between Model Architecture and In-Context Learning Ability 🔴
- やや意外なことであるが、いくつかの状態空間モデルの変種は、Transformer よりも頑健な文脈内学習者であることがわかった。
- 状態空間モデルは推論時にコンスタントな大きさのメモリフットプリントを持つため、この結果は、文脈内学習を膨大な数の文脈内事例にスケールアップできる可能性を将来的に開くものである。
- A 2-Dimensional State Space Layer for Spatial Inductive Bias 🔵
- ViT の各変換ブロックの先頭に我々のレイヤーを組み込むことで、複数の ViT バックボーンやデータセット間で性能が大幅に向上することを確認した。
- この新しいレイヤーは、無視できる量の追加パラメータと推論時間でも有効である。
- 我々のレイヤーを搭載した視覚 Transformer は、位置エンコードなしでも効果的な性能を示す。
- 「Vision Mamba の論文は position emcoding を加えると良くなったみたいな話だった気がするから、知見が逆だな」
context に関する話
- Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs (oral) 🟣
- 認識された構造に基づいて、我々は適応的な方法で KV キャッシュを構築する
- ローカルコンテキストを強調するアテンションヘッド上の長距離コンテキストを退避させ、特別なトークンを中心とするアテンションヘッド上の非特別なトークンを破棄し、すべてのトークンに広くアテンションするアテンションヘッドに対してのみ標準 KV キャッシュを採用する。
- 「Transformers are multi state RNNs? ってこれと同じ?」
- How do Language Models Bind Entities in Context? 🔴
- 文脈が複数の実体に関する事実を記述している場合、LM は属性を対応する実体に正しく結合しなければならない。
- LM の内部活性が、実体と属性の位置に適切な結合 ID ベクトルを示すことにより、結合情報を表現することを示す。
- さらに、結合 ID ベクトルは部分空間を形成し、しばしばタスクを越えて伝達されることを示す。
- この結果は、LM が文脈の中で記号的知識を表現するための解釈可能な戦略を学習することを示す。
- 文脈の活性化を研究することは、LM の認知を理解する上で有益な方向性を示すものである。
マルチモーダル系
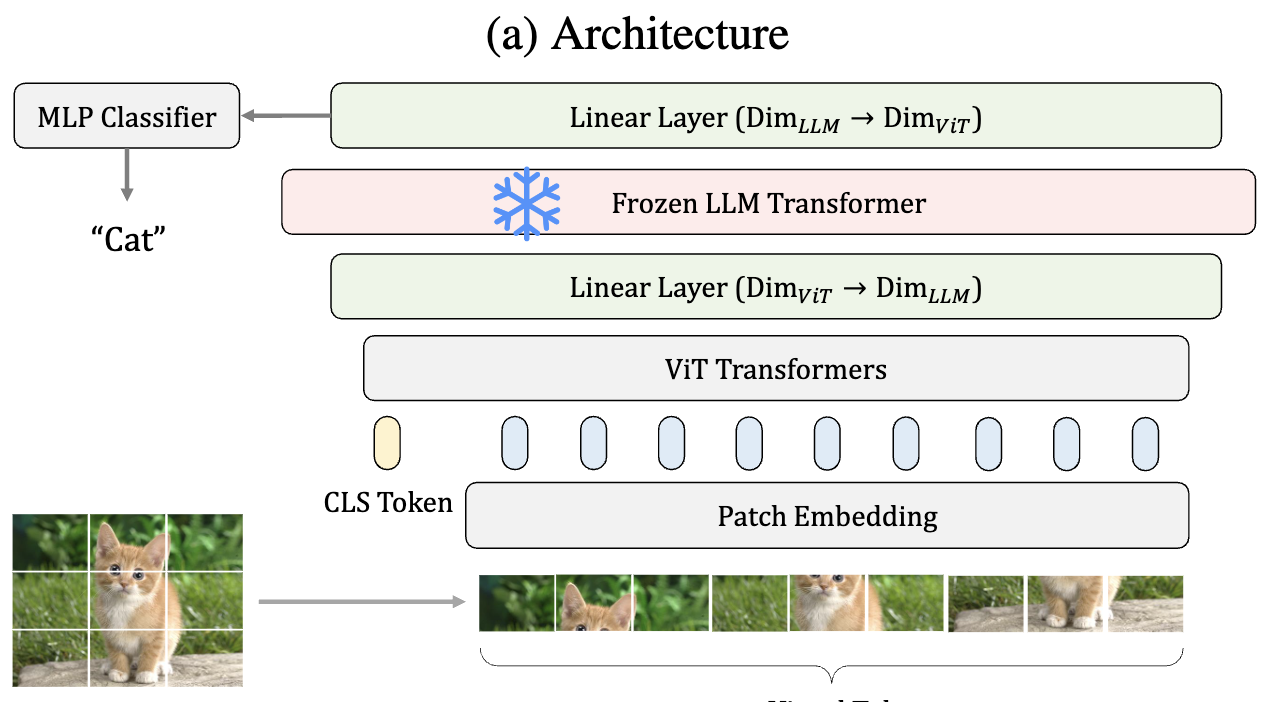
- Frozen Transformers in Language Models Are Effective Visual Encoder Layers (spotlight) 🟡
- この論文では、LLM が、テキストデータのみで訓練されているにもかかわらず、言語がない場合の視覚的課題に対して驚くほど強力なエンコーダーであることを明らかにする。
- 図を見たほうが言ってることのエグさが伝わる
![]()
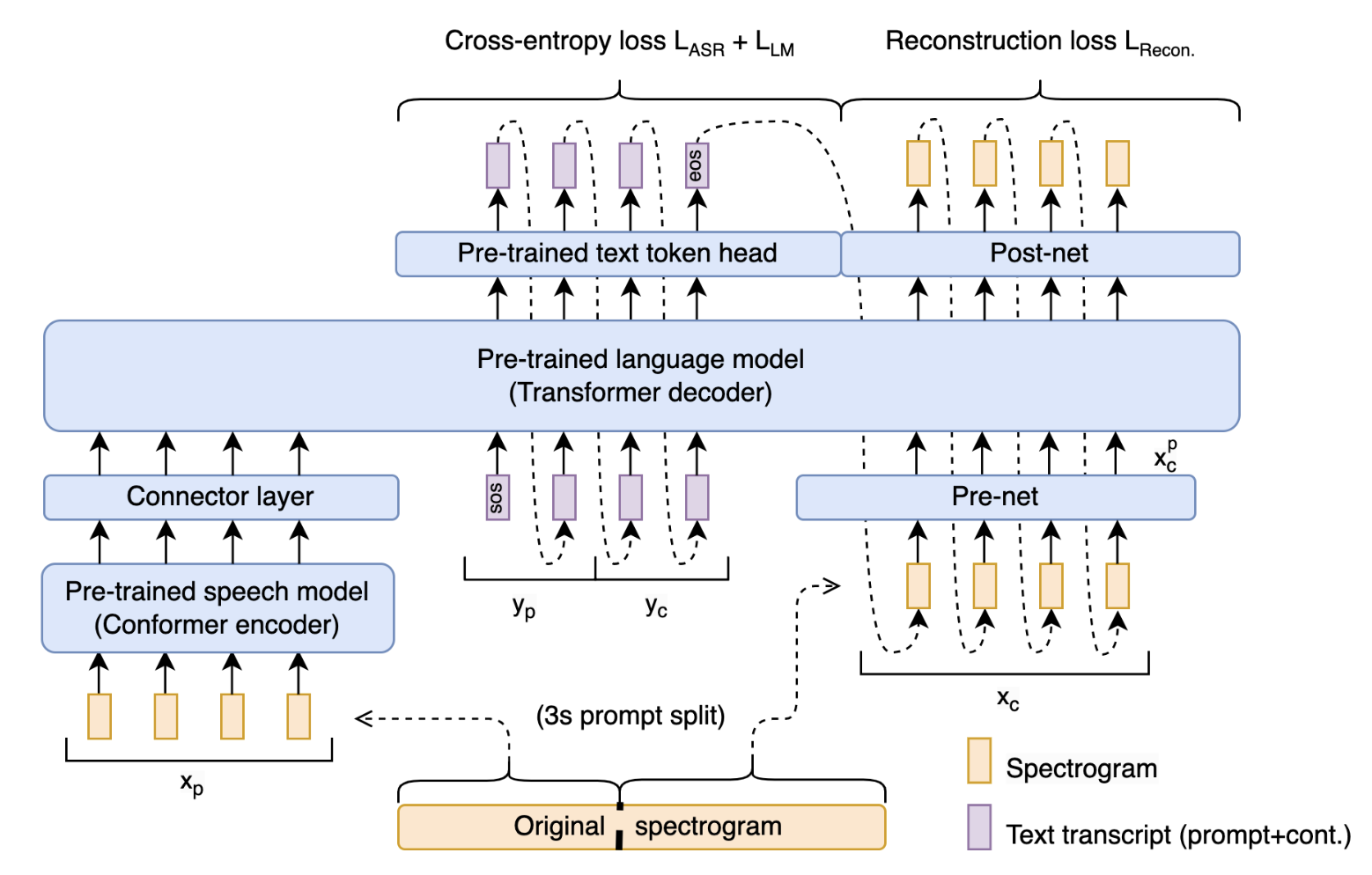
- Spoken Question Answering and Speech Continuation Using Spectrogram-Powered LLM 🟡
- LLM に事前学習済みの音声エンコーダを持たせることで、我々のモデルは音声入力を受け取り、音声出力を生成できるようになる。
- 「発想は上の手法と近いのかな?」
![]()
- The Hidden Language of Diffusion Models 🔵
- 普通に図がおもろい
![]()

データセット系
- Navigating Dataset Documentations in AI: A Large-Scale Analysis of Dataset Cards on HuggingFace 🔵
- ダウンロード数トップ 100 のデータセットカードの 86.0%が、Hugging Face コミュニティによって提案されたすべてのセクションを埋めているのに対して、ダウンロード数ゼロのデータセットカードのうち、これらのセクションをすべて埋めているのはわずか 7.9%である。
- OpenWebMath: An Open Dataset of High-Quality Mathematical Web Text 🔵
- HTML 文書からテキストと LaTeX コンテンツを抽出し、定型文を除去する方法、および品質フィルタリングと重複排除の方法について詳述する。
その他
- AutomaTikZ: Text-Guided Synthesis of Scientific Vector Graphics with TikZ 🔴
- text-to-text からビットマップグラフィックスを生成することが注目されているが、科学的な図ではベクターグラフィックスが好まれることが多い。
- TikZ を、科学図表の中間表現として利用することを提案する。
- 120k の TikZ 図とキャプションからなる、最初の大規模 TikZ データセットである DaTikZ を紹介する。
- モデルの重みとデータセットとともに、我々のフレームワーク AutomaTikZ を公開する。
- TabR: Tabular Deep Learning Meets Nearest Neighbors in 2023 🔵
- 最近提案された「GBDT フレンドリー」ベンチマークでは GBDT モデルをも上回る。
- Language Modeling Is Compression 🔵
- 予測モデルがロスレス圧縮機に変換できること、またその逆も可能であることは、以前から確立されている。
- 「まずそれが驚き、特に逆」
- 我々は、大規模言語モデルが強力な汎用予測器であること、圧縮の視点がスケーリング則、トークン化、文脈内学習に関する新しい洞察を提供することを示す。
- 予測圧縮の等価性によって、(gzip のような)どんな圧縮器でも条件付き生成モデルを構築できることを示す。
- 予測モデルがロスレス圧縮機に変換できること、またその逆も可能であることは、以前から確立されている。
感想
仮に自分用レコメンドモデルを作ったとしても、そいつのことと信用できなくて結局全部読むんだよね