論文 URL: https://arxiv.org/abs/2312.00752
僕の脳内を記してるだけで説明する気はないゾイ
SSM について
- bilinear の離散化しか知らなかったから ZOH で exp が出てきたのが初見だった。
- diagonal SSM が主流となり S4 の式変形テクニックは必要なくなった模様。
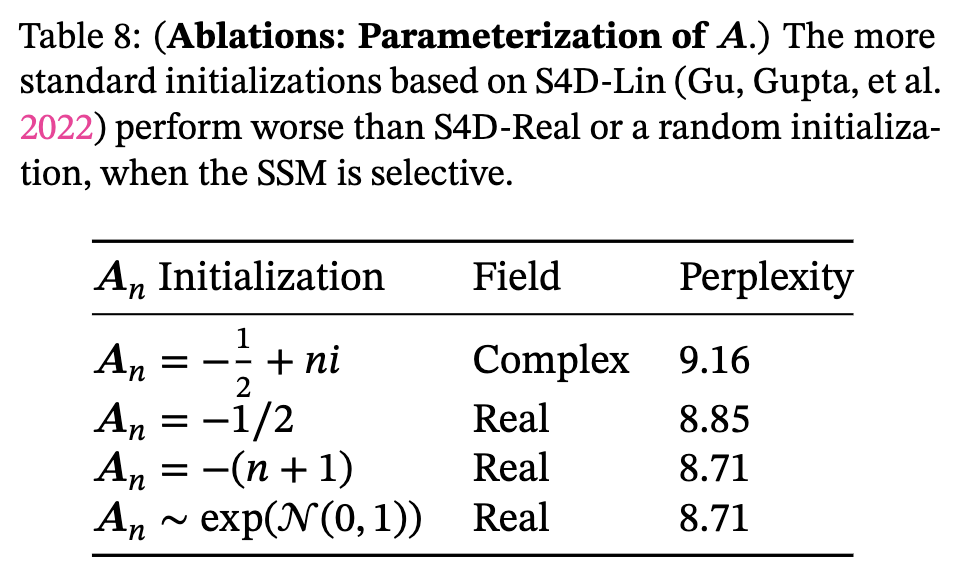
行列 A もランダム初期化で良いそうなので HiPPO らしさも無くなりそう。![]()
- S4D のときは雑な初期化だと上手くいかないと言われてたけど、GSS で解決されてた模様。
- 離散化により $A$ を $\overline{A}$ にする等の操作は健在なので、$A$ の初期化が単純になったからといって HiPPO らしさは健在。(追記: 2024-01-20)
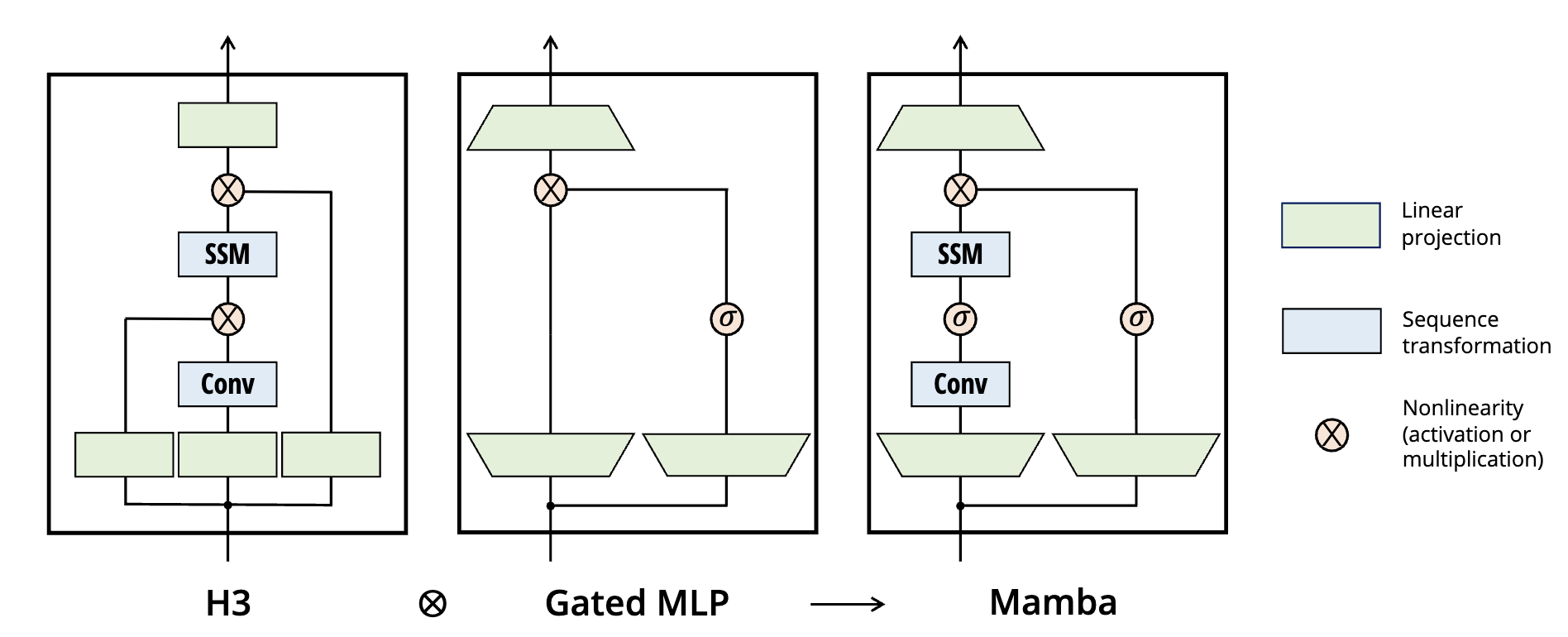
Convolution について
- all prior SSMs models must be time- and input-invariant in order to be computationally efficient
- 逆に言えば mamba では conv が使えないってこと?
- mamba で conv できない理由が理論的に納得できていない。
$A^L$ が $A_1 A_2 \cdots A_L$ になっちゃうからな気がするが、どうせまた天才に解決されそう。- カーネルが $[…,\overline{C_2 A_2^2 B_2},\overline{C_1A_1B_1},\overline{C_1B_1}]$ となるから $A_{t-1}^{L-1}$ の計算が $A_t^{L}$ に活かせないというのが理由かな? (追記: 2024-01-20)
- 一度に配列全体を処理できる conv よりも逐次的に処理する selective scan の方が早いのは全く納得できてない。
- 勉強会でアルゴリズムの説明をしていただいて納得した (https://speakerdeck.com/kurita/mamba?slide=43)。このアルゴリズムは log だが、conv も FFT すれば log なので同じくらいになりそう。というか、causal-scan が対数時間って衝撃的。(追記: 2024-01-20)
- Fig. 3 における conv って説明されてなかったような。H3 読まなきゃだめか。こっちの conv のお気持ち全く理解できてないんだよな。
![]()
Selective について
- これに関しては別の記事等で考察する。(追記: 2024-01-20)
- RNN の入力ゲートのように、入力 x を取捨選択するイメージ。
![]()
- この式を見る限りだと、何かを select したら過去の記憶が薄れるように見える。
- これで長距離を記憶できるというのが謎い。gating を理解してないので SSM 以前の問題。
- しかも文章の途切れ目で過去を全部忘れる Boundary Resetting の話も出てきたりして謎が深まる。
- この式を見る限りだと、何かを select したら過去の記憶が薄れるように見える。
ただ、著者は gating と selective に明らかな違いがあることを強調してる。gate なんも分からん。
(Approx. A, Selection) we view it as most closely related to the gating mechanism of traditional RNNs, which is a special case(Theorem1) and also has a deeper history of connections to SSMs through variable (input-dependent) discretization of∆. We also eschew the term “gating” in favor of selection to clarify the overloaded use of former. More narrowly, we use selection to refer to the mechanistic action of a model to select or ignore inputs and facilitate data interaction along the sequence length (Section3.1).
(Approx. B.2, Selective S4) For example, we hypothesize that it (=gating) would not solve the Selective Copying task because simply masking out the irrelevant inputs does not affect the spacing between the relevant ones (indeed, the Selective Copying task can even be viewed as coming pre-masked if the noise tokens are embedded to 0).
- S4 のときは $\Delta$ はそんなに強調されてなかった印象。これが selective を生み出す発端となるほど重要なパラメータとは思わなかった。
- HiPPO の時点で試みてはいたらしい。
- 離散化したときに生まれる変数が離散的なタスクを実行するときの鍵になるのは納得感ある。
- induction heads task において、クエリに対して適切な答え返せるの結構気持ち悪い。
- 記憶の cache が attention は行列なのに対して selective はベクトル。”記憶” ってそんな効率的な形式にできるものか?
- 先行研究では S5, QRNN, SRU が特に似てるらしい。
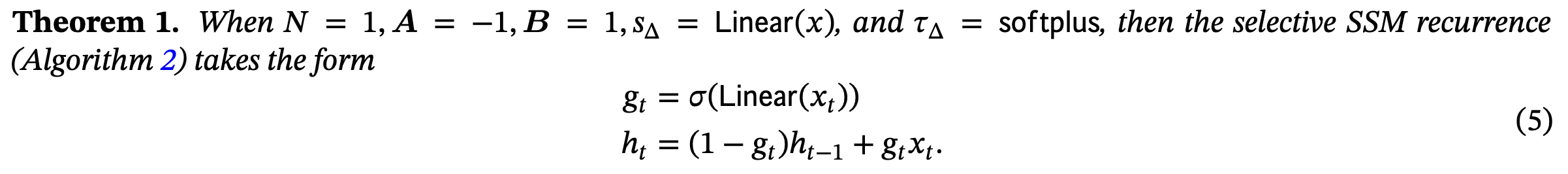
Implementation について
- ハードウェア分からんので、早いなら全部 SRAM で良くねとか思っちゃう。まあ、転送速度やメモリとか色々あるんだろうけど。
- メモリサイズが、BLD (入力) → BLDN (中間) → BLN (出力) と変わるから、サイズが拡大する内部処理を SRAM で完結させると嬉しいらしい。
- BLDN の部分は back prop のために保存せずに再計算すれば転送速度が 1/N になって、その方が早いってことかな。ハードウェア実はそこまでむずくない…?
Attention について
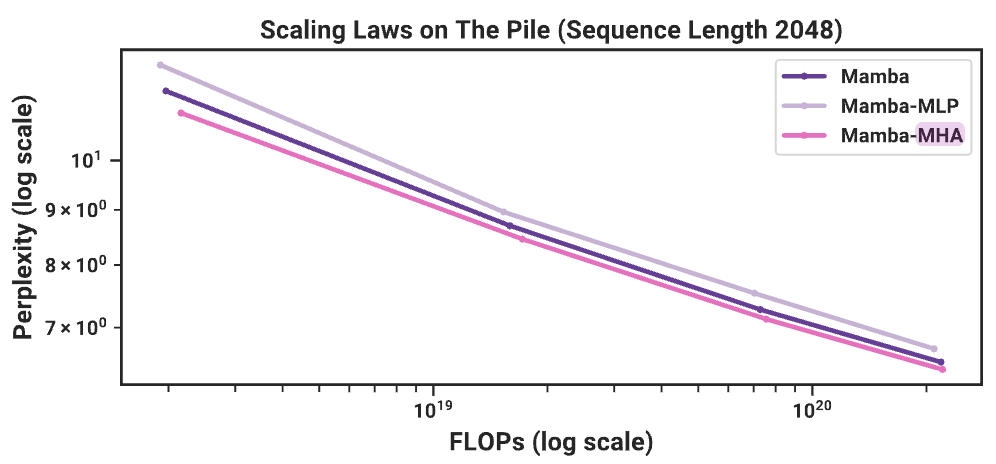
(Fig. 9) やはり、精度では attention には敵わない?
- 全記憶は
ズルすぎる強すぎる。 - ただ、全部使うとノイズも取り込んでしまうので linear な selective が匹敵するのも分かる。
下図の差は負けているというよりも遅れているなので別に待てば良いだけな気がする。
![]()
- 全記憶は
感想
- NLP で 1M tokens も一度に入力されるケースってなんだ?
- もし、無いなら context が制限されてる Transformer でも良くない?という気持ちになる。
- 千ページ単位のテキストくらい?知らんけど(← 本来の意味で)。対話だといくら長く続いてもここまで必要ない気がする。なんかのリポジトリくらいの規模?
- この論文における 1M tokens っていうのは実験で試した最大値であって実は無限かも知れない。
- であれば、本来の魅力は 1M という数字自体ではなく、100 tokens で訓練したモデルが推論時に 1000 tokens まで汎化するという能力。
- ちなみに、NLP で 1M tokens 扱えるとは多分言ってない。
- toy data で 1M: 実データに通じるか分からない。
- 音声で 1M: 連続データでの実験結果が離散データの NLP に通じるか分からない。
- DNA で 1M: 語彙サイズが小さすぎるので NLP に通じるか分からない。
- 上に対する補足: Mamba のことを「1M tokens を記憶できる」と解釈するのは危険。無視ができるというのが今回提案された Selective の肝なのだから、タスク完遂に不要な token は 1M tokens からガンガン無視している。(追記: 2024-01-20)
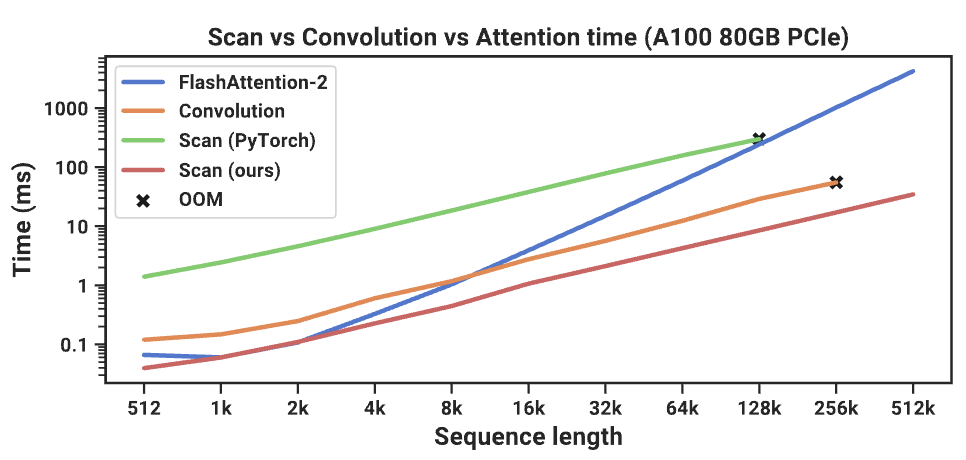
効率化の研究は cuda kernel と共にある。この図はハードウェア初学者にはかなり残酷かも。
![]()
- 数年経てば SSM の環境が整うかも知れないが、モデルに一工夫加えるとなると cuda skill が必須になっちゃうかも。
- パーツごとに関数を呼び出せるライブラリが提供されれば、パーツを色々組み合わせることは許されるかも知れない。
- 人間の記憶って attention 風なのか selective 風なのかどちらでもないのか(この分野なんも知らんけど)
- 少なくとも生きれば生きるほどパンクする attention ではなさそう。
- ただ、有限サイズの KV cache のような箱を臨機応変にメモリ開放して使い回ししてるかもしれない
- selective なのか?
- 人間って聞いた情報をその場で取捨選択している気はあまりしない。気づいたら忘れてる。
- でもそれって、新しい情報が “選択” されたから知らぬ間に忘れたことになってるのか?
- 「おっしゃー、あの記憶忘れるか」とは誰も思わないよね。sparse attention はそれをしてる感ある。
- 少なくとも生きれば生きるほどパンクする attention ではなさそう。
inductive heads task が研究したくなるくらい面白かったが、これ 読むの辛そう。←読んだ。(追記: 2024-01-20)